After Facebook changed its name to meta, "financial doom" did not end, but the technical style was as bold as ever. Although the company's share price has fallen by 30% since February 2022, its market value has lost more than $250 billion. However, this has not affected the spiritual world and work motivation of developers. This week, the crazy move of a small group of programmers from meta caused a great uproar in the global AI developer community——

Meta AI laboratory announced that it would open its own language model opt (open pre trained transformer) and contribute all the code unreservedly.
It is no exaggeration to say that this is a milestone in the artificial intelligence circle.
Since the establishment of this large-scale language model called opt, various parameters and capabilities have accurately benchmarked openai's gpt3, even its shortcomings. The reputation of the latter in the global academic circles and the continuation works of online novels that can be seen everywhere must not be repeated.
In short, this is a deep learning algorithm model that uses a large number of online texts and books for training, and can string words and phrases together to form wonderful texts.
It can generate complex sentences and sometimes even read the same as human writing (for a superficial understanding of GPT, see this super algorithm that makes Post-00 crazy). To some extent, its magical artificial text imitation ability is regarded as a huge breakthrough on the road to real machine intelligence.
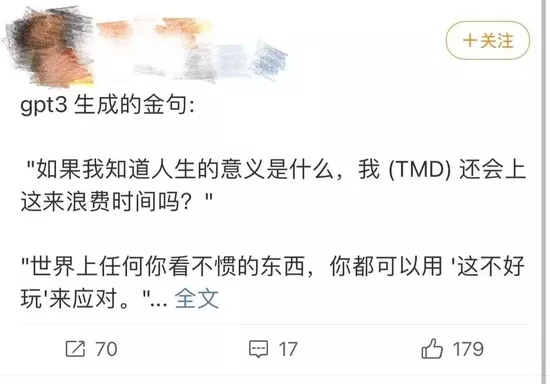
Gpt3 generated text
However, the cost of "cultivating" large models is the expensive labor cost and thousands of graphics cards. Therefore, many scholars believe that opening up this large model is almost impossible to happen to large technology companies "walking on the edge of monopoly".
For example, openai's gpt3 has been roughly estimated by experts and invested at least $10 million. Later, in order to get rid of the current situation of being unable to make ends meet, they promoted gpt3 as a paid service - only providing API, but not opening the model itself and underlying code.
However, meta said it would distribute training models with different parameter sizes and details of "how opt is built and trained" to researchers.
It also includes a more than 100 page algorithm training log - every error and crash recorded in the laboratory, the process of training and adding data, and effective and ineffective strategies.
"Considering the calculation cost, these models are difficult to copy without a lot of money. For a few models that can be called through API (gpt3 in this case), it is difficult to study if the complete model weight cannot be obtained." They clearly expressed their attitude in the abstract of OPT's paper,
"Therefore, we launched opt (a pre training transformation model with only decoder), with parameters ranging from 125m to 175B, with the goal of fully and responsibly sharing it with interested researchers."

"It's really open."
A Chinese developer who "is going to see their implementation" checked the meta AI website and told Hu olfactory that this is really good news. "Judging from the existing data, the whole training code has been posted. Meta is great."
Make good use of collective strength
This time, open source has been highly recognized by the academic community, and some scientists even call it a great move.
On the one hand, how a powerful technology is born in a closed enterprise elite team has always been the focus of public curiosity, including academia;
On the other hand, the advantage of "open source" lies in the use of collective strength to solve problems. Therefore, it has long been advocated by people of insight in Silicon Valley - the more people participate, the faster the technological breakthrough will come and the faster the loopholes will be filled.
Although most people almost only remember gpt3 (because it is the best "generalist" so far), in fact, in addition to meta, Google and Microsoft have launched similar large models in 2020, they are criticized for "transparency" because they do private research "behind closed doors".
For example, the "dismissal of Google artificial intelligence ethics scientists" in 2021 triggered a year long "critical tsunami", which was all caused by a paper on "major hidden dangers hidden in the large language model".

Timnit gebru, an AI ethics scientist unjustifiably dismissed by Google
Yes, gpt3 are not only flawed, but also very deadly. Although most of the blame lies behind the human text.
The startup latitude launched a semi open adventure game AI dungeon based on gpt3 in 2019. But I didn't expect that with the increase of users, openai monitored that some players used this high-level technology to spontaneously generate children's sex scenes.
Although the foul language generated by users using gpt3 has also been widely criticized, it still makes the public uproar. This is also the first time that the outside world has realized the deeper dark side of large models such as gpt3. Therefore, latitude has added an audit system, but it has caused a series of troubles related to the user experience.

However, "the more dangerous it is, the more it cannot avoid danger". This is also one of the key reasons why Facebook claims to choose openness.
Joelle Pineau, head of meta AI, admitted that the team could not solve all problems, including ethical bias and malicious words in the text generation process. Therefore, they sincerely invite heroes from all over the world to learn together; In fact, this is also a kind of mutual supervision.
"I think the only way to build trust is extreme transparency."
We checked the download channel provided by meta and found that the laboratory has set different download conditions according to the parameter scale of each model: below 30 billion parameters are optional; The 175 billion parameter numerical model, that is, opt with the same size as gpt3, needs to fill in the application form to prove that it is used for non-commercial purposes, and can be downloaded only after being approved.
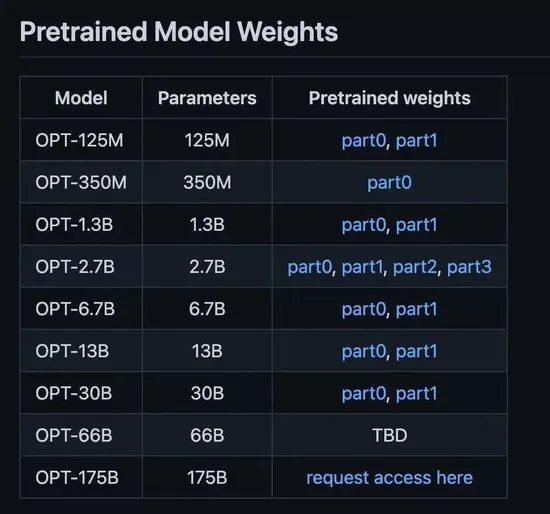
Over the mountains, it is still a mountain
Of course, this approach is commendable in theory, but a bigger problem arises: if you want to use this large model with 175 billion parameter values, it means that your computer should be able to carry it.
In other words, you need to have enough computing power, which can be directly converted into "financial resources".
"If a parameter is fp32, it is four bytes in size. The 175 billion parameter value is equivalent to 700 billion bytes, about 700g of video memory space. Now an ordinary video card is 20GB." A developer praised meta's approach to Hu olfactory, but he believes that the model is still an unbearable weight for the ordinary developer group.
"Although different parameters can be put in the framework of different graphics cards, according to personal experience, there is still a lack of open source and mature framework."
Therefore, up to now, this large open source model is still an "internal game" belonging to large technology companies, large laboratories and academic institutions with sufficient funds.
A start-up company that tried to make a Chinese version of gpt3 sighed that they were also trying to realize the text ability that gpt3 can achieve, but it was limited by limited computing power.
In fact, in addition to giants, the commercialization problem that gpt3 has been difficult to solve is the fundamental reason why most enterprises are on the sidelines. Although large language models have become one of the hottest trends in the field of artificial intelligence in the past few years. But at least for now, in addition to the advantages of brand marketing, the input-output ratio of openai is not satisfactory.
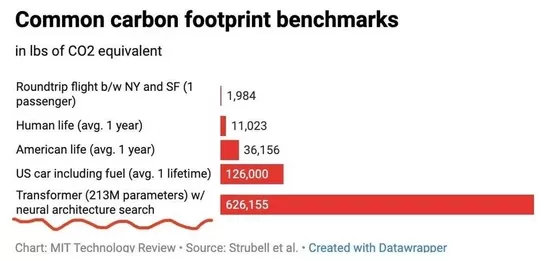
Picture from MIT
In addition, it is generally recognized in western society that the huge energy consumption they bring is an original sin compared with technological breakthroughs.
A paper published by scientist Emma strubel and his collaborators in 2019 revealed the unimaginable environmental destructive power of large language models in carbon emissions (above).
They found that a specific language model trained with a neural structure search method (NAS) could produce 284 tons (626155 pounds), above) of carbon dioxide, which is about the total emission of five cars for five years;
The basis of Google search engine, Bert language model training, produces 0.65 tons of carbon dioxide, strubel warned, which is equivalent to the carbon emission of a passenger's round-trip flight from New York to San Francisco.
More importantly, these figures should be regarded as the "most conservative values": only the model cost in one-time training.
Therefore, considering energy efficiency and environmental costs, many Western scientists and developers believe that to some extent, the training and development of large models also allows large enterprises to plunder environmental resources, and these costs will be shared equally among all people. Therefore, they do not want enterprises to join the queue of large models.
"Although it is unconscious, it will only increase the blow to marginalized people."
Open source business returns are huge and intangible
Many times, people will question the open source model as follows:
What can be more incredible than "two employees from rival companies can cooperate for the same goal and give their results free"?
For example, the Android system that may be clear to even primary school students is based on the open source Linux operating system. This means that anyone can view the core code of most Android phones, modify and share it.
In fact, "open source" is to provide a long-term technical cooperation mode of "advantages far outweigh disadvantages" for different interest groups - I can use the unique elements you add, so you won't miss the version of my iteration.
This "mutually beneficial" attitude makes the seemingly incredible "cooperation" possible. After more than 100 years of repeated correction, it has already become a normal state. Today, Linux is developed and maintained by more than 15000 programmers around the world.
In the field of artificial intelligence, the most famous case is Google's deep learning open source framework tensorflow. It has become one of the standard frameworks for developing artificial intelligence applications. Interestingly, when tensorflow opened its source in 2015, the outside world also raised the same questions as the meta open source model:
As an opener, why should google give up something so important to its search business?
Part of the reason is mentioned above - if external developers make the software better, the software can meet many needs of Google's commercialization in the future. Just like at present, the commercialization of large models is still unclear, so the openness and dominance of preliminary work become crucial.
According to Google's own data, more than 1300 outsiders have helped upgrade iterations on tensorflow. The improved tensorflow provides strong support for relevant paid services on Google cloud.
In addition, we should never underestimate the huge marketing value that open source software brings to enterprises.
Its most first-class "delivery effect" is to attract and retain a group of top talents. I don't know how much expensive human capital it saves for large factories. This also perfectly echoes the current situation that meta began to shrink the recruitment scale.
Of course, the time difference and convergence effect of excellent open source software will make it difficult for latecomers to form a climate in a short time. Tensorflow and the past of domestic in-depth learning of open source framework are the best examples.
Therefore, meta's decision will put openai in an awkward position - although it has a great reputation, it is a start-up company after all. From another point of view, in the process of looking for commercial landing, large factories curb their opponents and win by means of openness and free. This kind of thing seems to happen forever.
But the advantage is that this will make a company realize that in the business world, there is no one minute to stop and never stop the pace of innovation - the second generation of Dali system recently released by them may be the best sign of jumping in the direction of text and visual integration with gpt3 as a springboard.
Author Yu Duotian
Produced by Tiger olfactory Technology Group