The author is a founder of the StarCraft open source community, the deputy secretary general of the China Open Source Alliance, and an engineer who has been working in open source for more than 20 years in well-known technology companies. He has personally experienced or witnessed the excellent practices of many engineers in the field of open source, and has also seen many Bad Cases. The article "How Engineers Approach Open Source" brings together many insights and experiences of the author, in addition to the "How Engineers Choose Open Source Software" presented in this article In addition to the "how engineers choose open source software" presented in this article, it also focuses on "how engineers customize and maintain open source software" and "how engineers use open source for personal growth". The topic Tan said, "I hope it will help engineers to grow better."
Author: Tan Zhongyi, Deputy Secretary General of China Open Source Promotion Alliance and founder of Xingze Open Source Community
As a technical engineer, the job task is to use technology to support and achieve the business goals that the company is focused on. In practice, a large amount of open source software is used and maintained, either actively or passively. According to statistics, each engineer will be exposed to thousands of open source software every year when doing R&D and operation and maintenance work in the enterprise. (Source: "2020 State of the Software Supply Chain" by Sonatype)
So how do you choose open source software? With so much open source software out there, how do you choose the right open source project to invest in based on your personal needs and business needs?
The first step is to clarify the attitude towards open source software, i.e., the use of open source software is inseparable at this stage. However, there are various risks associated with the use of open source software, including open source compliance, security, efficiency and other issues. To simplify it into one sentence: efficient, secure, and compliant use of open source software within an enterprise requires adherence to that enterprise's internal rules for open source software, including how it is introduced and how it is maintained.
Going back to the question of exactly how to choose specific open source software, there are several latitudes that can be referenced.
- on demand
- Based on technology trends
- Depending on the stage of the software adoption cycle
- Based on the maturity of the open source software
- Based on the quality indicators of the project
- Based on the governance model of the project
The first step in choosing open source software is to define the need, i.e. what is the purpose of choosing this open source software, whether it is for personal learning; or for meeting the needs of to B customers; or for meeting the needs of internal service development. For different purposes, the choice of open source software is oriented completely differently. (Note: The latter two scenarios need to consider the need for enterprise open source compliance first, referring to each enterprise's internal open source compliance requirements.)
for personal learning **
Let's start with the choice of open source software for personal learning, then it depends on what the specific purpose of the learning actually is. Is it to learn a more popular technology to improve personal technical knowledge structure to expand personal technical vision; or want to see the corresponding open source technology project specific implementation, to be used as a reference for internal project technology development; or want to be targeted for the next job technical preparation.
For the former, it is obviously a matter of choosing whatever technology is most popular and what you lack; for the second purpose, it is generally a targeted selection of well-known open source or innovative software in that technology area, i.e. a feature that I currently need or that is not well implemented in my current project and I need to see how others have implemented it. The last one, obviously, is to prepare for the position needs and technology stack requirements for the next job and to choose according to the high threshold of the technology stack requirements.
However, note that when you choose open source software from your personal needs, you usually need to write a small project to practice, such as a demo program or a test service, because you do not have to consider the subsequent long-term maintenance, so you can do all kinds of exercises according to your personal ideas and personal R & D habits, without following the internal development process and quality requirements, and without considering the stability of the open source software and community Maturity and so on, just enjoy learning and reference code.
meets to B Customer's needs **
The software selected for open source software for development is required to be provided to customers, often possibly delivered as a private cloud. When selecting open source software based on such needs, care is taken to strike a good balance, that is, to balance the needs of the customer with the needs of the enterprise's own technology planning or long-term planning for the product.
To enter the customer's IDC environment as a private cloud, it is necessary to integrate with the upstream and downstream projects of the customer's development and operation environment. This time depends on the needs of the customer, there may be some customers have specific requirements for open source software, such as the requirement to use HDFS and a specific version. The reason why the customer will specify the name of the software and the specified version may be because it is currently more familiar with this version, there may be because of the previous software and version provided by other hardware and software vendors, the purpose of the specified is to facilitate the integration and subsequent use and maintenance.
If such requirements are in line with the long-term development needs of the enterprise project or product, then it is possible to meet them completely. If the A-side is so strong that there is no other way than to meet his requirements, then it is better to choose the software and version specified by the customer.
However, if the long-term development needs of their own projects or products are not consistent, and the specific project or version is negotiable with the A, then you need to negotiate with the customer to come up with a mutually acceptable result, that is, the choice of a specific open source software and version to achieve both customer satisfaction and buy-in, but also to achieve their own delivery costs can be controlled, but also to meet the long-term development needs of their own projects or products.
For example, the customer is using an older version of Java, but the enterprise's to-B delivery software requires a higher version of Java. Then you need to negotiate with the customer, either to switch to the version that the enterprise wants, and help the customer to complete the upgrade of the existing system; or you can only reduce the Java version of your own software requirements, and may also need to modify some of your own code, and may also modify some of the software's dependent components. This scenario is a choice with many objective constraints and requires negotiation with the customer, its own product manager and the architect.
meeting internal service needs
If the scenario is to meet the needs of internal services, that is, the choice of open source software to build the service is for internal business or end-user to use, common in the major domestic Internet companies of the Internet service system and a variety of mobile phone App. this time the development and maintenance of the project has greater autonomy, and to B delivery business is completely different. At this point, when choosing open source software, we must consider the development and maintenance costs, and also consider the stage of the business using the service.
(1) If the service provided is for innovative business, innovative business is generally a trial and error business, which needs to be adjusted at any time according to changes in market conditions and the current state of implementation, and it is likely that the project will be cancelled after three months. In this case, the "brown fast and fierce" development approach is more appropriate, without too much consideration for the maintainability and scalability of the system, the most familiar software technology stack used by the R & D team, and then use the underlying technical support team (such as the infrastructure team) to provide a mature and proven underlying technology platform can be, the most important The most important thing is to build out the system as soon as possible and then iterate quickly with the product.
This time you need to minimize the learning and development costs of the existing R & D O&M team, without much consideration of maintainable costs, because the need to brown fast and furious to pile up the system, validate the product requirements and business model is the most important, time is most important. If you find a market opportunity, follow up quickly, and after you get a firm foothold, you can use a time-saving but resource-intensive approach (commonly known as "stacking machines") to scale, or use the "fly the plane while changing engines" model for rewriting is more cost-effective. For a business or project in the startup phase, speed trumps all.
(2) If you choose open source software to build out the computer software system or services need long-term maintenance, such as for mature business use in the company, or for the shortcomings of the mature platform in the company to upgrade the system and to replace the original product, then under the premise of meeting business needs, consider the maintainability of the system becomes the most important thing.
When choosing the corresponding open source software, whether it is mature and stable; whether the secondary development is friendly; whether the operation and maintenance costs are more cost-effective, i.e., more machine and bandwidth efficient; whether the operation and maintenance operations are convenient, e.g., whether the common expansion and scaling operations can be done efficiently, automatically and losslessly; whether it is easy to Upstream to the upstream open source community, etc., all these things become key considerations. In this case, the cost of developing a system may be less than 1/10th of the cost of the entire system lifecycle. So the focus is on maintainability while meeting the requirements.
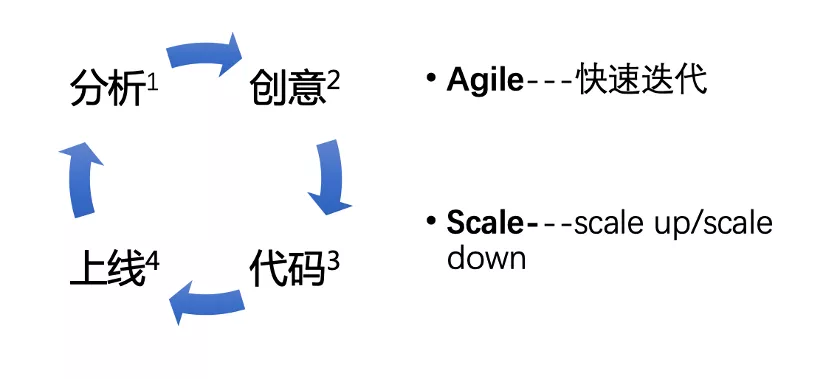
As the above diagram shows, the development of modern computer software or services is a continuous running cycle and iterative process. It starts with market analysis, then moves to the idea phase, then to the coding phase, and finally to the go-live phase to complete the deployment and validation of the application, and continues after go-live based on the data feedback received.
This cycle of iterative process, obviously for an industry in a competitive business, the faster the iteration, the better, but also need to have the ability to quickly elastic, low-cost scaling, that is, the product direction is right, then hurry to expand the system, to undertake the fast-growing traffic, to achieve rapid growth; if the product direction is not right, you need to hurry to reduce the capacity, to save the relevant hardware and human resources, to invest If the direction of the product is not right, you need to scale down, save the relevant hardware and human resources and invest in a new trial and error direction. If enterprise A can iterate various products and strategies at a lower cost and faster speed, it obviously has a more competitive advantage than enterprise B, which has a slower iteration speed and higher cost.
There is a huge amount of open source software available nowadays, and there are many open source projects under almost every category. How do you make a choice for a specific need? One suggestion is to make your choice based on technology trends. That is, the way computer systems iterate nowadays is Agile + Scale.
Clearly, open source software that can support rapid iteration of computer systems and that can be easily and inexpensively scaled flexibly is worth a long-term investment. When learning and using a new open source software, the learner is looking for the software to be as low barrier to learning as possible. A popular open source software, the internal implementation can be as complex as possible, but it must be user-friendly for the user. Otherwise, even if the innovation level is good and the ease of use is bad, only geeks can learn and master it, and the innovation chasm is hard to cross.
Docker, for example, took the world by storm at a very fast pace after its advent. The reason why so many engineers love Docker is because of its features - adding new features on top of the traditional container system, including encapsulating the application and underlying dependencies into a container image, which is versioned and can be stored and distributed in large quantities through a centralized image repository.
Docker first solves the long-standing problem of standardizing development, testing, and go-live environments for engineers, and can support developers in rapid iteration. At the same time, it uses a unified image repository for image distribution, and the underlying technology of lightweight virtual machine or container can be pulled up very quickly, so the system using Docker can be easily scaled up elastically. At the same time, because the application app is encapsulated in an image, it can be better abstracted and reused logically according to the design principles of Domain Model.
Obviously, such a technique is worth learning and mastering by every engineer who develops computer systems. Because he can bring great convenience.
In contrast, although Control Group (cgroup) + Namespace technology was available and integrated into the Linux kernel long before Docker, and Google's borg-related papers were published, it was not easy for the average technical development team to harness containers and deploy container systems on a large scale within the company. But it's not easy for the average technical development team to harness containers and deploy them at scale within the company.
I have the impression that after the borg paper appeared, only BAT-level Internet companies in China have a small elite R & D team to develop and use container management systems, such as the team responsible for Matrix system development in Baidu, the team responsible for Pounch system development in Ali, Tencent also has a small team responsible for the research of container systems.
But apart from that small group of teams, more engineers are not putting containers to use in large volumes because of the difficulty of learning them. And a technology like Docker, which follows the technology trend of agile and elastic scaling very well, and offers very good user ease of use, was quickly used by a very large number of engineers right out of the gate, and became the default standard in the market.
These compliant open source software are worth choosing and investing in.
Another example is Spark, which has replaced MapReduce in the mainstream of distributed computing because it solves the problem of low performance caused by frequent IO operations during distributed computing, and has improved ease of use.
Software, as a product of intellectual activity, has its own life cycle, which is generally represented by the technology adoption curve of software.
Open source software is also a type of software, and all follow the laws of technology adoption in software. (As shown in the figure below)
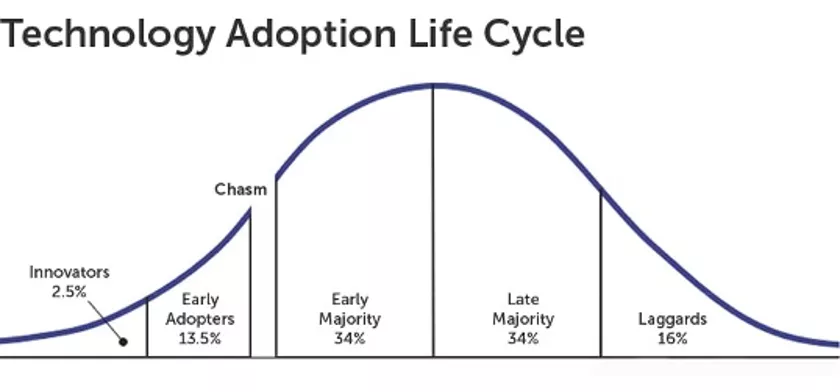
An open source software typically goes through 5 phases from creation to demise. From Innovators (2.5%), to Early Adopters (13.5%), then across the chasm to Early Majority (34%), then to Late Majority (34%), and finally Laggards (16 percent).
The vast majority of open source innovation projects that do not successfully cross the domain divide, i.e., move from the early adoption stage to the early mass stage, die out. So, if you are choosing an open source project that needs to be used and maintained over time, it is more sensible and scientific to choose a project that is in early mass or late mass status.
Of course if just an individual wants to learn a new thing, look at open source projects in innovator status, or look at projects in "early adopter" status.
Be careful not to look at projects in decline (Laggards) either from a long-term development system perspective or from a personal learning perspective. For example, at this stage, i.e. 2022, there is no need to go for projects like Mesos, Docker Swarm, etc. Since Kubernetes became the default standard for container scheduling technology classification, these two projects are already in decline and their parent companies have given up. At this stage, if you still put more effort into development and maintenance, unless a really strong A-side demands it and drops money in front of the engineers to force them to use it.
InfoQ, gartner, and thoughtworks update their respective technology adoption curves every year and publish them.
From InfoQ's judgment of various popular technologies in the BigData space in 2022, open source software such as Hudi, Clickhouse, Delta Lake, etc. are still in the innovator stage, i.e., adoption in industry is still relatively low, and students who want to learn new projects can focus on them. But now these open source software is not yet suitable for application inside the mature application scenarios that require long-term maintenance.
Note that the technology adoption curves of these well-known tech media are updated annually, so don't forget to take note of when they were published when making your reference.

InfoQ's verdict on the various popular technologies in the BigData space in 2022
Another point is that open source software is selected based on the maturity of the open source software itself. That is, whether the open source software is released regularly, whether it is in a state of multi-party maintenance (even if a company's strategy has changed and it is no longer maintained, there are other companies that support it in the long term), whether it is well documented, and other dimensions to assess the maturity.
For open source software maturity models, the open source community has a number of maturity models for measuring open source projects, of which the Apache Open Source Software Foundation's project maturity model is one of the better known, which takes the latitude of assessing an open source project and divides it into seven dimensions.
- Code
- License and Copyright (software license and copyright)
- Release
- Quality
- Community (community)
- Consensus Building
- Independence
Each of these dimensions has several checks. For example, in the case of Independence, there are two more checks: one is whether the project is independent of any corporate or organizational influence, and the other is whether the contributors are acting in the community on their own behalf or as representatives of a company or organization.
Apache Foundation Top Level projects are judged on a combination of these dimensions during the graduation phase. Only projects that meet all the criteria are allowed to graduate from the Apache Foundation's incubation status and become Top Level projects. This is what forces me to prefer Apache Top Level projects.
Also, the Criticality score for OpenSSF projects (see https://github.com/ossf/criticality_score is also a good reference metric, it will measure the number of community contributors, frequency of commits, frequency of releases, number of dependencies and other indicators to determine the importance of an open source software in the open source ecosystem. I won't go into details here, interested students can refer to its information, personally I think it is a worthy reference direction, but this score is still in the early stage, far from the ideal state.
Obviously, the quality of code of some open source software is just better than the quality of other open source software. There are times when you need to choose open source software by the quality of the project.
This time, we need to look at some metrics that have been widely proven to be more effective in the industry.
One of the MTTU is a metric recommended by SonaType, a leading open source supply chain software provider.
MTTU (Mean Time to Update): The average time it takes for open source software to update the version of a library it depends on. For example, an open source software A depends on open source library B. Suppose the current version of A is 1.0 and the version that depends on B is 1.1. One day the version of open source library B is updated from 1.1 to 1.2, and then some time later, open source software A also releases a new version 1.1, in which the version that depends on B is updated from 1.1 to 1.2. This time interval, i.e., the time between the upgrade from open source version B to 1.2 and the release of the new version 1.1 of open source software A, is called Time to Update.
This time reflects the ability of the development team of open source software A to update its dependency versions synchronously according to the update cycle of the dependency libraries.Mean Time to Update is the average upgrade time of this software. The lower the value, the better the quality, indicating that the person responsible for the software is updating the versions of the various dependencies very quickly and fixing the security vulnerabilities caused by the various dependencies in a timely manner.
According to SonaType, the MTTU for updates and upgrades of open source software in the industry is getting shorter and shorter. The average MTTU for Java-based open source software on the Maven Central repository was 371 days in 2011, 302 days in 2014, 158 days in 2018, and 28 days in 2021. It can be seen that as open source software repositories are updated more frequently, the software that uses them has also accelerated the rate of updated versions and the MTTU has reduced to less than 10/1 of the original time relative to 10 years ago.
Of course MTTU is only an indirect latitude of project quality. The history of whether important high-risk security vulnerabilities are exposed, whether the fix response is fast and timely, etc., are also important dimensions in the quality evaluation of open source projects.
The security department of some large companies will constantly evaluate the security situation of open source software, set certain open source software that repeatedly occurs high risk security vulnerabilities, but the repair is not timely as insecure software, included in the internal open source software blacklist to the internal public, and require various business development teams no longer use these software. If it is not possible to migrate to a new software system due to R&D and manpower issues, it is also necessary to migrate these old services to a relatively closed network environment to reduce the potential damage caused by the risk. At this point, it should clearly be necessary to comply with the company's security regulations and stop using blacklisted open source software.
There is another dimension, which is considered in terms of the community governance model of open source projects and applies to projects that require development and maintenance over time.
The Community Governance Model (GCM) focuses on how the project or community makes decisions and who makes them. Is everyone allowed to contribute or are there a few? Are decisions made by voting or by authority? Are plans and discussions visible?
Three common governance models for open source communities and open source projects are as follows.
Single company-led: is characterized by the fact that the design, development and release of the software are controlled by a single company, and no external contributions are accepted. Development plans and release plans are not made public, nor are discussions about them, and the source code is only made public when a release is made. For example, Google's Android system.
Dictator-led (there is a proper name "Benevolent Dictatorship" which translates to "benevolent dictator"): characterized by a person who controls the development of the project, who has strong influence and leadership, and is usually the founder of the project. For example, the Linux Kernel is run by Linus Torvalds, and Python was previously led by Guido Van Rossum.
Board-led: is characterized by a set of people who make up the project's board of directors to decide on major matters for the project. For example, the Apache Software Foundation's projects are decided by the project's PMC, and the CNCF's Foundation's decisions are the responsibility of the CNCF Board (many technical decisions are delegated to the Technical Oversight Committee under the CNCF Board).
Personal opinion and experience in prioritizing the selection based on how the open source community behind the open source software is governed is as follows.
Preference for Apache graduate projects, which have a clear intellectual property situation and are being maintained by at least three parties over time.
Sub-optimal selection of key projects from other open source foundations, such as the Linux Foundation, which is highly operational and often has one or more large companies behind each key project.
Choose a company-led open source project carefully, as that company's open source strategy may be adjusted at any time and it is likely that it will no longer support the project on an ongoing basis, for example Facebook is a company that has abandoned many pits.
Try not to choose projects that are open-sourced by individuals, who are more casual and particularly risky, but don't rule out certain projects that are already highly visible and run a long-term maintenance model, such as the Vue.js open source software by well-known open source author Evan You.
This is a personal recommendation for choosing similar open source software projects in order of priority, and is only a personal opinion, so feel free to discuss.