In less than a week, AI painters have "advanced" again, which is still a big step - the kind that directly generates video in one sentence. Enter "a woman running on the beach in the afternoon", and a short clip of 4 seconds and 32 frames will pop up immediately:

Or enter "a burning heart" to see a heart wrapped in flame:

This latest text video generation AI is Tsinghua & Cogvideo, a model produced by Zhiyuan Research Institute.
As soon as the demo was put on the Internet, it became popular. Some netizens were already eager for papers:
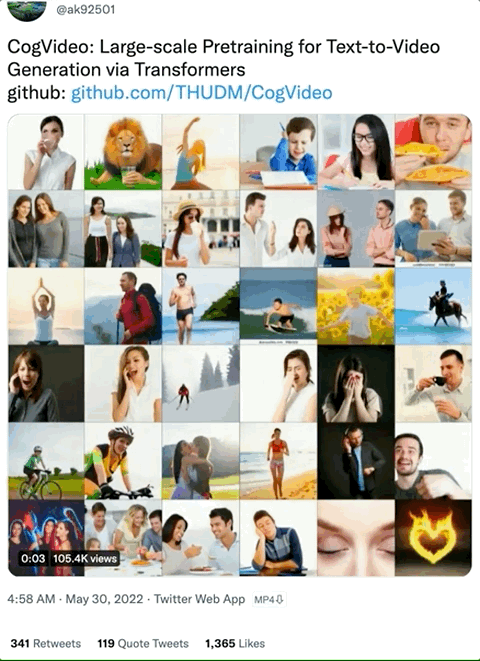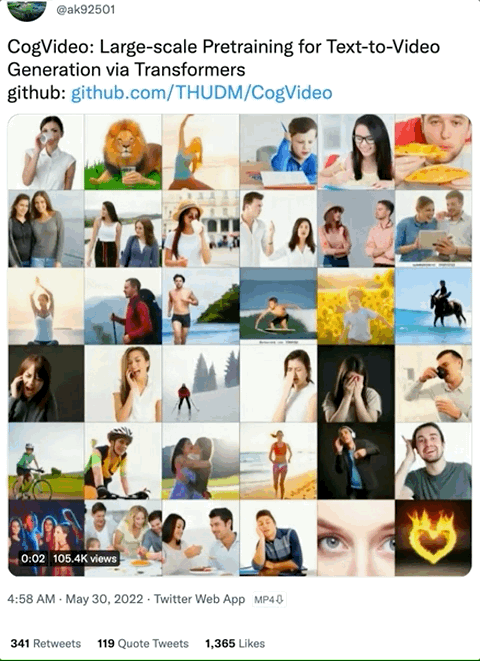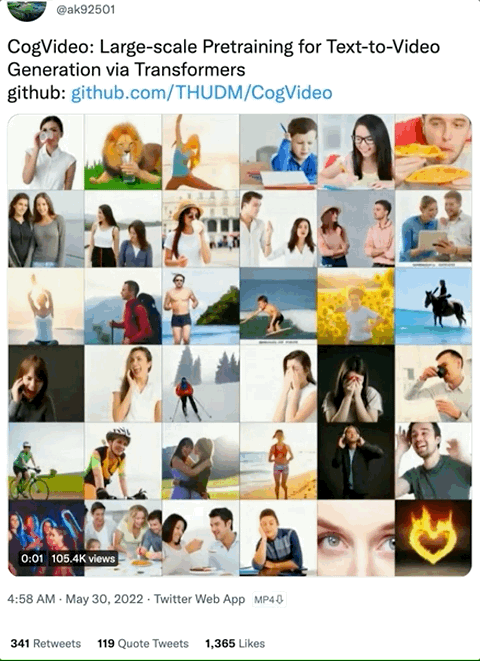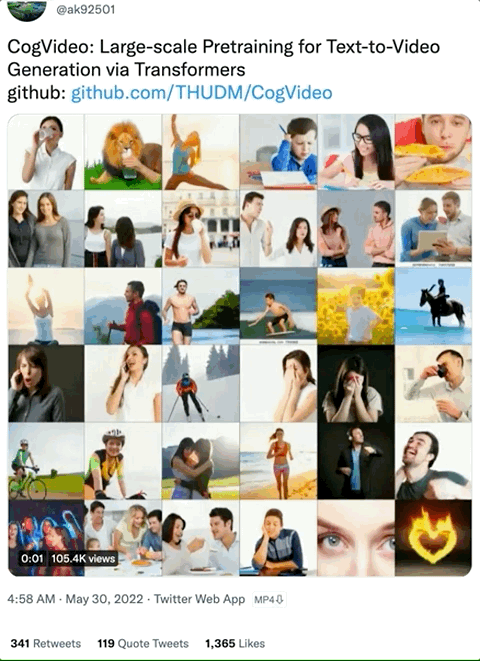
Cogvideo "comes down in one continuous line" from the text image generation model cogview2. This series of AI models only support Chinese input. If foreign friends want to play, they have to use Google Translation:

After watching the video, netizens called "this progress is too fast. You know, the text image generation models dall-e2 and imagen have just come out."

Some netizens also imagined that if we continue to develop at this speed, we will soon see that AI can generate 3D video effects in VR head display in one sentence:
So, what is the origin of this AI model named cogvideo?
Generate low frame video and then insert frame
The team said that cogvideo should be the largest and first open source text generated video model at present.
In terms of the design model, the model has a total of 9billion parameters and is built based on the pre trained text image model cogview2, which is divided into two modules.
In the first part, based on cogview2, several frames of images are generated through text. At this time, the frame rate of the composite video is still very low;
In the second part, the generated images will be interpolated based on the bidirectional attention model to generate a complete video with higher frame rate.
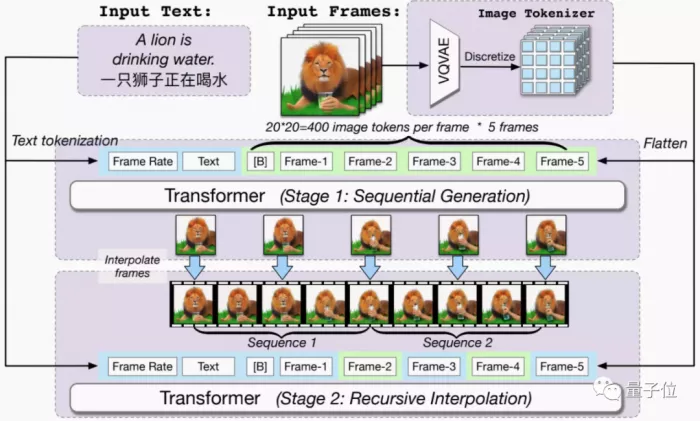
In training, cogvideo used a total of 5.4 million text video pairs.
This is not only to match the text and video directly and "plug" them into AI, but also to split the video into several frames and add an additional frame mark to each frame of the image.
This avoids AI seeing a sentence and directly generating several identical video frames for you.
Among them, the video of each training was originally 160 × 160 resolution, up sampled by cogview2 (enlarged image) to 480 × 480 resolution, so the final generation is 480 × 480 resolution video.
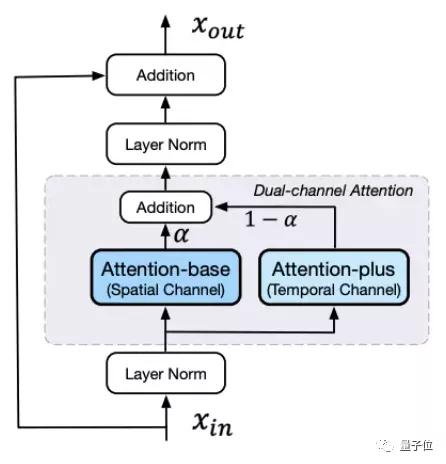
As for AI framing, the bidirectional channel attention module is designed to enable AI to understand the semantics of the front and back frames.
Finally, the generated video is smooth, and the output of 4-second video frames is about 32.
Highest score in human assessment
This paper evaluates the model using both data testing and human scoring methods.
The researchers first tested cogvideo on two human motion video datasets, ucf-101 and dynamics-600.
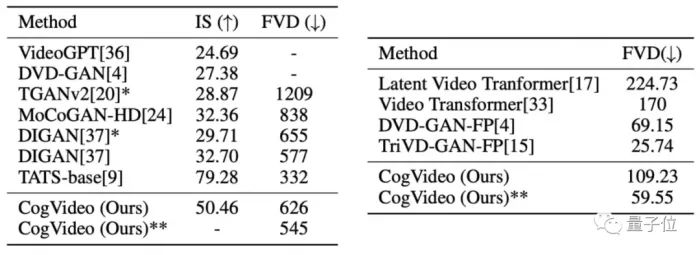
Among them, FVD (FR é Chet video distance) is used to evaluate the quality of the overall video generation. The lower the value, the better; Is (inception score) mainly evaluates the quality of generated images from two aspects: sharpness and diversity of generation. The higher the value, the better.
Overall, the video quality generated by cogvideo is at a medium level.
However, from the perspective of human preference, the video effect generated by cogvideo is much higher than that of other models. Even among the best generation models at present, cogvideo has achieved the highest score:
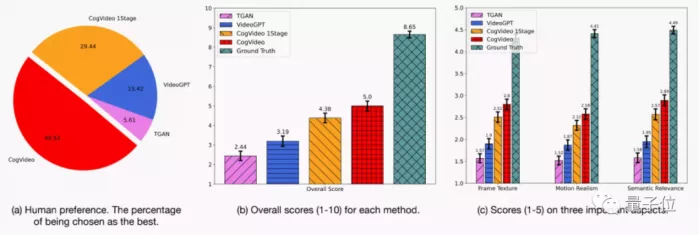
Specifically, the researchers will give volunteers a scoring table and ask them to randomly evaluate the videos generated by several models according to the video generation effect, and finally judge the comprehensive score:

The first work of cogvideo, Hong Wenyi and Dingming, the second work, Zheng Wendi and the third work, Xinghan Liu, are all from the computer department of Tsinghua University.
Previously, Hong Wenyi, Dingming and zhengwendi were also the authors of cogview.
Tangjie, the instructor of the thesis, is a professor of the computer department of Tsinghua University and the academic vice president of Zhiyuan Research Institute. His main research interests are AI, data mining, machine learning and knowledge mapping.
For cogvideo, some netizens said that there are still some places worth exploring. For example, both dall-e2 and imagen have some unusual prompts to prove that they are generated from 0, but the effect of cogvideo is more like "patching up" from the data set:
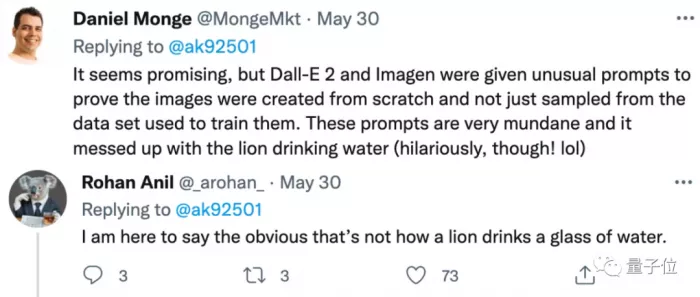
For example, the video of a lion drinking water "by hand" is not in line with our conventional cognition (although it is very funny):

(is it a bit like a magic expression bag with two hands for birds)

However, some netizens pointed out that this paper provides some new ideas for the language model:
Training with video may further unlock the potential of language models. Because it not only has a large amount of data, but also contains some common sense and logic that are difficult to be reflected in the text.

At present, the code of cogvideo is still under construction. Interested partners can go to squat for a while~
Project & Thesis address: