The artificial intelligence (AI) world is still considering how to deal with the amazing ability display in dall-e 2, that is, the ability to draw / draw / imagine almost anything But openai is not the only one studying something like this Google research has released a similar model it has been working on -- and it says it's even better

Imagen is a generator based on text to image diffusion, which is based on the large converter language model.
Text image model accepts text input such as "a cycling dog" and generates corresponding images. This work has been done for many years, but recently there has been a great leap in quality and accessibility.
One part is to use diffusion technology, which basically starts with a pure noise image, and then slowly improves it bit by bit until the model thinks it can't make it look more like a cycling dog than it has done. This is an improvement on top-down generators. These generators may make funny mistakes in the first guess, while other generators can easily be led astray.
The other part is to improve language understanding by using large language models of converter method, but it and some other recent advances have brought convincing language models such as gpt-3 and others.

Imagen first generates a small (64 × 64 pixels), and then "super-resolution" it twice to 1024 × 1024。 But this is not like ordinary upgrading. Based on the original image, AI's super-resolution creates new details that are harmonious with small images.
In the first picture, the dog's eyes are only three pixels wide. But in the second picture, its width is 12 pixels. Where do the details come from-- AI knows what a dog's eyes look like, so it produces more details when drawing. Then, when the eye is drawn again, this happens again, but the width is 48 pixels. Like many artists, it starts with the equivalent of a rough sketch, then fills it up in research and implements it on the final canvas.
This is not without precedent. In fact, artists using AI models are already using this technology to create works that are much larger than those that AI can handle at one time. If you divide a canvas into several pieces and then super-resolution them respectively, you will eventually get bigger and more complex things, and you can even repeat this.
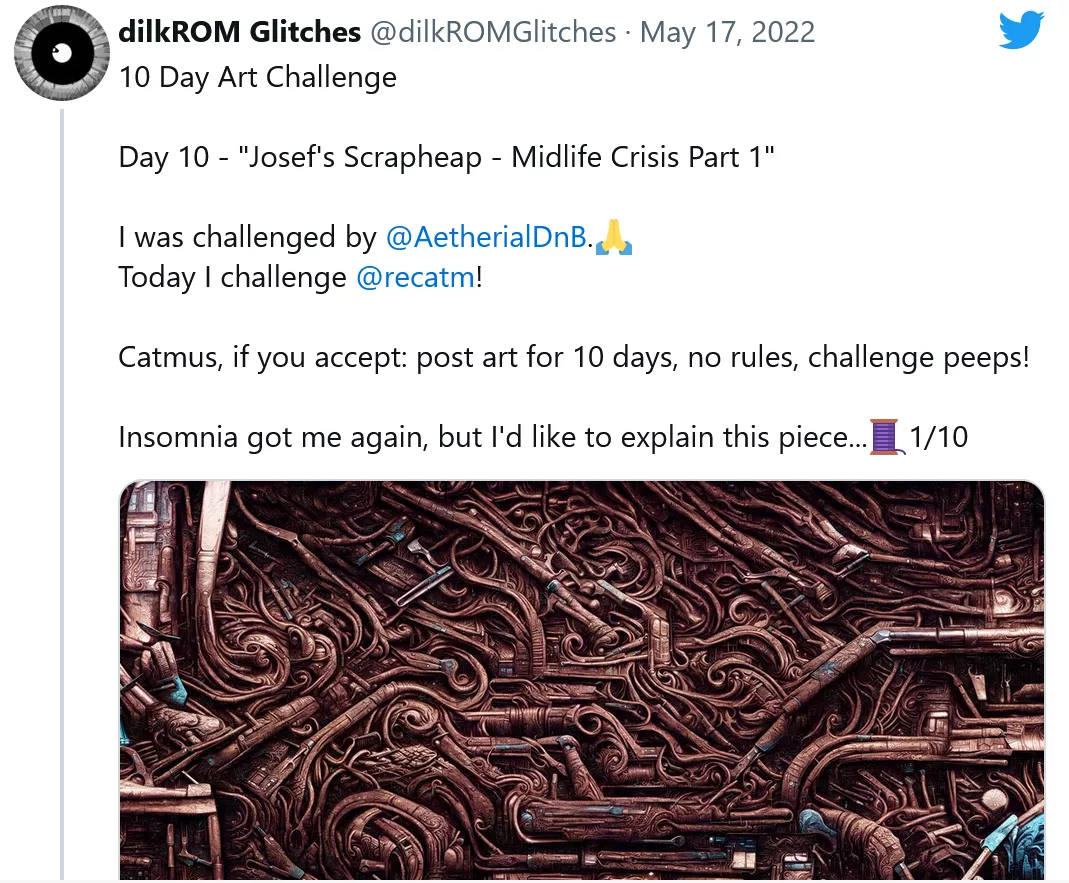
Google researchers say imagen's progress covers several areas. They said that the existing text model can be used in the text coding part, and its quality is more important than simply improving visual fidelity. This makes sense intuitively, because a detailed picture of nonsense is certainly worse than a slightly less detailed picture.
For example, in the paper describing imagen, they compared the results of "a panda doing latte art" with dall-e 2. All the images of the latter show the latte art of pandas; In most of the images of imagen, pandas are doing (latte) art.

In Google's test, imagen is ahead of the test of human evaluation, both accuracy and fidelity. Although this is quite subjective, it can even match the perceived quality of dall-e2. Until today, it is considered to be a huge leap ahead of everything else, which is quite remarkable.
However, openai is one or two steps ahead of Google in several aspects. Dall-e 2 is more than just a research paper. It is also a private beta. People are using it just as they used its predecessor and gpt-2 and 3. Ironically, the company with "open" in its name has been focusing on commercializing its text to image research, but the lucrative Internet giant has not tried yet.
This can be seen from the choices made by the researchers of dall-e 2. They planned the training data set in advance and deleted anything that might violate their own guidelines. The model can't be made even if it wants to make nsfw. However, Google's team used some large data sets known to include inappropriate materials. In the insightful section of the imagen website describing "limitations and social impact", the researchers wrote:
"Downstream applications of text image models are diverse and may affect society in complex ways. The potential risk of abuse has attracted attention to responsible open code and presentation. At present, we have decided not to release code or public presentation.
The data requirements of text image model lead researchers to rely on large, mostly unorganized, network collected data sets to a large extent. Although this approach has led to rapid advances in algorithms in recent years, data sets of this nature often reflect social stereotypes, oppressive views and derogatory or other harmful associations to marginalized identity groups. Although a subset of our training data is filtered out of noise and bad content such as pornographic images and toxic language, we also use the laion-400m data set, which is known to contain a wide range of inappropriate content, including pornographic images, racist slogans and harmful social stereotypes. Imagen relies on text coders trained on uncoordinated network scale data and inherits the social biases and limitations of large language models. Therefore, imagen has the risk of encoding harmful stereotypes and expressions, which guided us to decide not to release imagen to the public without further safeguards. "
While some may scoff at this, saying that Google is worried that its AI may not be politically correct, this is an immoral and short-sighted view. The quality of an AI model depends on the data it trains, not that every team can spend time and energy deleting the really terrible things found by these searchers when collecting millions of images or billions of word data sets.
Such bias is intended to be shown during the research process, which exposes how the system works and provides an unrestricted testing ground for identifying these and other limitations.
Although for many people, removing systemic bias is a lifelong project, AI is easier, and its creators can delete the content that leads to its misconduct first. Maybe one day AI will need to write in the style of racist and sexist experts in the 1950s, but at present, the benefits of including these data are too small and the risks are too great.
In any case, imagen, like other similar technologies, is obviously still in the experimental stage, and it is not ready to be used in ways other than strict human supervision.