In a soundproof crate there is one of the worst neural networks in the world. After seeing the image of the number 6, the neural network pauses for a moment, and then displays the number it recognizes: 0. Peter McMahon, a physicist and engineer at Cornell University, led the development of the neural network. He smiled sheepishly and said that it was because the handwritten numbers looked scrawly.
Logan Wright, a postdoctoral visiting McMahon laboratory from NTT Institute, said that this device usually gives the correct answer, but he also admitted that mistakes are also common.
Although the performance is mediocre, this neural network is a pioneering research. The researchers turned the crate over, revealing not a computer chip, but a microphone tilted toward a titanium plate fixed to the speaker. Unlike neural networks running in the digital world of 0 and 1, this device operates on the principle of sound. When Wright gives a digital image, the pixels of the image are converted into audio, and then the speaker vibrates the titanium plate, making the laboratory full of weak chirps. That is to say, it is the metal echo that performs the "read" operation, rather than the software running on the silicon chip. The success of this device is incredible, even its designers are no exception. McMahon said, "whatever the function of vibrating metal, it should not have anything to do with the classification of numbers written by the opponent." In January this year, the research team of Cornell University published a paper in the journal Nature entitled "deep physical neural networks trained with backpropagation". This paper introduces the original reading ability of this device, which brings hope to McMahon and others. It tells them that after many improvements, this device may bring revolutionary changes to computing< a href="" target="_blank">
Paper link: https://www.nature.com/articles/s41586-021-04223-6 When it comes to traditional machine learning, computer scientists find that the larger the neural network, the better. For specific reasons, please refer to the article in the figure below. This article called "computer scientists prove why bigger neural networks do better" proves that if you want the network to remember its training data reliably, over parameterization is not only effective, but also mandatory< a href="" target="_blank">
Article address: https://www.quantamagazine.org/computer-scientists-prove-why-bigger-neural-networks-do-better-20220210/ A neural network filled with more artificial neurons (nodes storing values) can improve its ability to distinguish dachshunds from Dalmatians, and can also successfully complete numerous other pattern recognition tasks. A truly huge neural network can complete writing papers (such as openai's gpt-3), drawing illustrations (such as openai's Dall · e, Dall · E2 and Google's imagen), and more difficult tasks that people think about. With more computing power, greater feats become possible. This possibility encourages efforts to develop more powerful and efficient computing methods. McMahon and a group of like-minded physicists advocate an unconventional approach: let the universe process data for us. "Many physical systems naturally perform certain calculations more efficiently or faster than computers," McMahon said He cites the wind tunnel as an example: when engineers design an aircraft, they may digitize the blueprint and then spend hours simulating the air flow around the wings on a supercomputer. Or they can put the aircraft in a wind tunnel to see if it can fly. From a computational point of view, the wind tunnel can immediately "calculate" the interaction between aircraft wings and air< a href="" target="_blank">
Note: Cornell University team members Peter McMahon and tatsuhiro Onodera are writing programs for various physical systems to complete learning tasks. Figure source: Dave Burbank wind tunnel can simulate aerodynamics and is a machine with specific functions. Researchers like McMahon are working on a device that can learn to do anything - a system that can adjust its behavior through trial and error to gain any new ability, such as the ability to classify handwritten digits or distinguish one vowel from another. The latest research shows that physical systems such as light wave, superconductor network and electronic branch flow can be learned . Benjamin scellier, a mathematician at the Federal Institute of technology in Zurich, Switzerland, said that he helped design a new physics learning algorithm. "We are reshaping not only the hardware, but also the entire computing paradigm." 1* learning and thinking * learning is a very unique process. Ten years ago, the brain was the only system capable of learning. It is the structure of the brain that inspires computer scientists to design the deep neural network, the most popular artificial learning model. Deep neural network is a kind of computer program that can be learned through practice. Deep neural network can be considered as a grid: the node layer used to store values is called neuron, and neurons are connected to neurons in adjacent layers through lines, which are also called "synapses". Initially, these synapses were just random numbers called "weights". To make the network read 4, the first layer of neurons can represent the original image of 4, and the shadow of each pixel can be stored in the corresponding neurons as a value. Then the network "thinks", moves layer by layer, and fills the next layer of neurons with neuron values multiplied by synaptic weights. The neuron with the largest median value in the last layer is the answer of the neural network. For example, if this is the second neuron, the network guesses that it sees 2. In order to teach the network to make smarter guesses, the learning algorithm will work in the opposite direction. After each attempt, it calculates the difference between the guess and the correct answer (in our example, this difference will be represented by the high value of the fourth neuron in the last layer and the low value elsewhere). Then, the algorithm goes back layer by layer through the network, and calculates how to adjust the weights to make the final value of neurons rise or fall as needed. This process is called back propagation and is the core of deep learning. By repeating multiple guesses and adjustments, back propagation guides the weight to a set of numbers, which will output the result through cascading multiplication initiated by an image.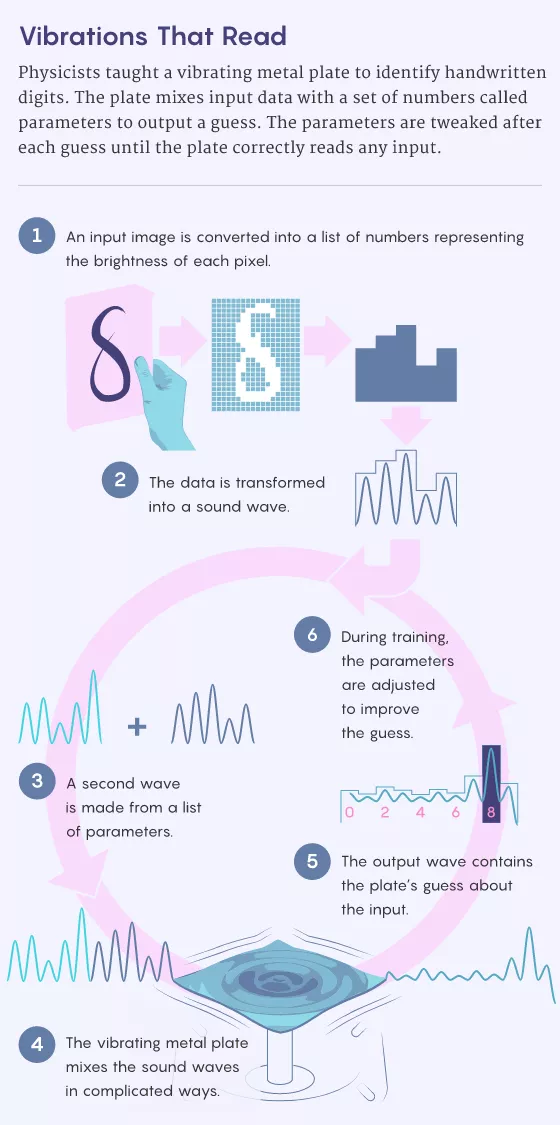
Source: Merrill Sherman, Quanta magazine, but compared with the thinking of the brain, the digital learning in the artificial neural network seems to be very inefficient. With less than 2000 calories a day, a human child can learn to speak, read, play games and more within a few years. Under such limited energy conditions, gpt-3 neural network, which can communicate smoothly, may take a thousand years to learn to chat. From the point of view of physicists, a large-scale digital neural network is just trying to do too many mathematical operations. Today's largest neural networks must record and manipulate more than 500billion numbers. This amazing figure comes from the paper "pathways language model (Palm): scaling to 540 billion billion billing parameters for breakthrough performance" in the figure below: 
Paper link: https://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html At the same time, the emerging tasks of the universe are far beyond the limits of the computer's meagre computing power. There may be trillions of air molecules bouncing around in a room. For a mature collision simulation, this is the number of moving objects that can not be tracked by the computer, but the air itself can easily determine its behavior every moment. Our current challenge is to build a physical system that can naturally complete the two processes required by artificial intelligence, which are the "thinking" of image classification and the "learning" required to correctly classify such images. A system that has mastered these two tasks is really using the mathematical power of the universe, not just doing mathematical calculations. "We've never calculated anything like 3.532 times 1.567," says scellier. "The system calculates, but implicitly by following the laws of physics." 2* thinking part * McMahon and co scholars have made progress in the "thinking" part of this puzzle. A few months before the outbreak of the COVID-19, McMahon set up a laboratory at Cornell University. He pondered a strange discovery. Over the years, the most outstanding image recognition neural network has become more and more deep. In other words, networks with more layers can better receive a pile of pixels and give labels, such as "poodle". This trend has inspired mathematicians to study the conversion realized by neural networks (from pixels to "poodle"). In 2017, several groups proposed in the paper "reversible architectures for arbitrary deep residual neural networks" that the behavior of neural networks is an approximate version of smooth mathematical functions< a href="" target="_blank">
Thesis address: https://arxiv.org/abs/1709.03698 In mathematics, a function converts an input (usually an x value) to an output (the y value or height of the curve at this position). In a particular type of neural network, the more layers, the better, because the function is not so uneven and is closer to an ideal curve. This study led McMahon to think. Perhaps through a smoothly changing physical system, people can avoid the blocking inherent in digital methods. The trick is to find a way to tame a complex system by training it to adjust its behavior. McMahon and his collaborators chose the titanium plate as such a system because many of its vibration modes mix incoming sound in complex ways. To make the tablet work like a neural network, they input a sound that encodes the input image (e.g. handwritten 6) and another sound that represents the synaptic weight. The peak and trough of the sound need to hit the titanium plate at the right time, so that the equipment can combine the sound and give the answer - for example, a new sound is the loudest in six milliseconds, representing the classification of "6"< a href="" target="_blank">
Note: a research team at Cornell University trained three different physical systems to "read" handwritten numerals: a vibrating titanium plate, a crystal and an electronic circuit from left to right. Source: the picture on the left is taken by Rob kurcoba of Cornell University; The picture on the right is taken by Charlie wood of quanta magazine. The team also implemented their scheme in an optical system where the input image and weight are encoded in two beams mixed by crystals and an electronic circuit that can similarly transform the input. In principle, any system with Byzantine behavior can do so, but researchers believe that optical systems have special prospects. Not only can crystals mix light very quickly, but light also contains a wealth of data about the world. McMahon imagines that the miniature version of his optical neural network will one day become the eyes of autonomous vehicle, which can recognize parking signs and pedestrians, and then input information into the car's computer chip, just as our retinas do some basic visual processing of incoming light. However, the Achilles' heel of these systems is that training them requires a return to the digital world. Back propagation involves a back running neural network, but negatives and crystals cannot easily decompose sound and light. Therefore, the team built a digital model for each physical system. Reversing these models on a laptop, they can use a back-propagation algorithm to calculate how to adjust the weights to give an accurate answer. Through this training, this titanium plate learned to classify handwritten digits, and the correct rate was 87%. The accuracy of the circuit and laser in the above figure is 93% and 97% respectively. The results show that "not only standard neural networks can be trained through back propagation," said Julie Grollier, a physicist at the French National Center for scientific research (CNRS), "it's beautiful." The research team's vibrating titanium plate has not yet made the computing efficiency close to the amazing efficiency of the brain. This device is not even as fast as the digital neural network. But McMahon thinks his device is amazing because it proves that people can not only think with their brains or computer chips. "Any physical system can be a neural network." He said 3* learning part * another difficult problem is how to make a system fully autonomous learning. Florian Marquardt, a physicist at the Max Planck Institute for Optical Science in Germany, believes that one way is to build a machine that runs upside down. Last year, he and a collaborator proposed a physical simulation of the back propagation algorithm that can run on such a system in the paper "self-learning machines based on Hamiltonian echo backpropagation"< a href="" target="_blank">
Thesis address: https://arxiv.org/abs/2103.04992 To prove this is feasible, they simulated a laser device similar to McMahon equipment with digital technology, encoding the adjustable weight in one light wave and mixing it with another input wave (encoding, such as image). They bring the output closer to the correct answer and use optical components to decompose the wave and reverse the process. "Miraculously," Marquardt said, "when you try the device again with the same input, the output tends to be closer to where you want it." Next, they are working with experimenters to build such a system. However, the system focusing on reverse operation limits the choice, so other researchers have completely left back propagation behind. Because they know that the way the brain learns is not a standard back propagation, their research has not been hit, but has gone further. "The brain is not backward propagating," says ssellier. When neuron a communicates with neuron B, "propagation is unidirectional."< a href="" target="_blank">
Note: Julie Grollier, a physicist of CNRS, has implemented a physics learning algorithm, which is regarded as a promising alternative to back propagation. Figure source: Christophe caudroy in 2017, scellier and yoshua bengio, a computer scientist at the University of Montreal, developed a one-way learning method called balanced propagation. We can understand how it works: imagine a network of arrows like neurons, whose directions represent 0 or 1, connected in the grid by springs as synaptic weights. The looser the spring, the harder it is to align the connected arrows. First, rotate the leftmost row of arrows to reflect the pixels of the handwritten numeral. Then, keep the leftmost row of arrows unchanged and let the disturbance spread out through the spring to rotate other arrows. When the flip stops, the rightmost arrow gives the answer. The point is that we don't need to train the system by flipping the arrows. On the contrary, we can connect another group of arrows showing the correct answer at the bottom of the network. These correct arrows will flip the above group of arrows, and the whole grid will enter a new equilibrium state. Finally, compare the new direction of the arrow with the old direction and tighten or loosen each spring accordingly. After many tests, the spring has obtained a smarter tension. Scellier and bengio have proved that this tension is equivalent to back propagation. "People don't think there can be a connection between physical neural networks and back propagation," Grollier said. "It's very exciting that things have changed recently." The initial work on balanced communication is theoretical. But in a forthcoming article, Grollier and CNRS physicist J é R é Mie laydevant describe the implementation of the algorithm on a quantum annealing machine manufactured by d-wave. The device has a network of thousands of interacting superconductors, which can naturally calculate how the "spring" should be updated like a spring connected arrow. However, the system cannot automatically update these synaptic weights 4* realize closed loop * at least one team has collected some components to build an electronic circuit that uses physics to complete all heavy work, and the work it can complete includes thinking, learning and updating weights. "We have been able to close the loop for a small system," said Sam dillavou, a physicist at the University of Pennsylvania< a href="" target="_blank">
Note: physicist Sam dillavou of the University of Pennsylvania has repaired a circuit that can be self modified during learning. Dillavou and his collaborators' goal is to imitate the brain. The brain is the real intelligence. It is a relatively unified system and does not need any single structure to give orders. "Every neuron is doing its own thing," he said. To this end, they constructed a self-learning circuit, in which the variable resistor is used as the synaptic weight, and the neuron is the voltage measured between the resistors. To classify a given input, the circuit converts the data into voltages applied to several nodes. The current passes through the circuit to find the path with the least energy dissipation, and changes the voltage when it is stable. The answer is to specify the voltage at the output node. The innovation of this idea lies in the challenging learning steps. Therefore, they designed a scheme similar to balanced propagation, which is called coupled learning. When one circuit receives data and "guesses" a result, another identical circuit starts with the correct answer and incorporates it into its behavior. Finally, the electronics connecting each pair of resistors automatically compare their values and adjust them to achieve a "smarter" configuration. This group described their basic circuit in the preprint last summer (see the figure below). This paper entitled "demonstration of decentralized, physics driven learning" shows that this circuit can learn to distinguish three types of flowers, with an accuracy of 95%. Now they are developing a faster and more powerful device< a href="" target="_blank">
Thesis address:< https://arxiv.org/abs/2108.00275 >
Even this upgrade cannot beat the most advanced silicon chips. But the physicists who built these systems suspect that although digital neural networks now look powerful compared with analog networks, they will eventually appear slow and inadequate. The digital neural network can only be expanded to a certain extent, otherwise it will fall into excessive calculation, but the larger physical network only needs to be itself. "This is a very large, fast-growing and ever-changing field. I am convinced that some very powerful computers will be made with these principles." Dillavou said. Original link: